How does r/hellofresh feel about hellofresh?
I started interviewing for hellofresh recently. Part of the job posting listed ‘experience with unstructured data’ - so I decided to take a look at the sentiment in the subreddit r/hellofresh about.. hellofresh!
Here’s an image of the recent reddit ‘hot’ 1000 posts from r/hellofresh:
Keep reading to see how this changes when we clean the sentiment analysis results and explore different estimates of centrality.
Introduction
HelloFresh Group currently operates in 18 countries across 3 continents. In addition to their core brand, they operate: Green Chef, EveryPlate, Chefs Plate, Factor_ , and Youfoodz. Truly a massive endeavor.
The core business is a meal kit delivery service where all of the ingredients + a recipe card are shipped to customers. Factor_ is their only ready to eat (RTE) brand so far. Part of any company’s success is going to be related to their ability to understand customer feedback - a type of data more commonly unstructured rather than structured.
Tools exist to quickly parse human language and get a sense of the general sentiment - without having to individually read and rank social media comments. In this post we’ll explore the Natural Language Toolkit (NLTK) Sentiment Intensity Analyzer with the VADER Lexicon. But First, we need to access the Reddit Posts through their official API toolkit - the Python Reddit API Wrapper (PRAW)
PRAW
The Python Reddit API Wrapper is Reddit’s latest library for interacting with their API. It handles all of the limitations and usage requirements. Most importantly - since Reddit no longer offers a totally free API - it obeys the ratelimit headers. This isn’t a big deal for us since we’re just requesting some read only access manually. If we were building a reddit app, then this would influence our costs and could accidentally be very expensive.
To sign up for an API key go to: https://www.reddit.com/prefs/apps/
Then to configure your reddit connection after installing via pip, do:
reddit = praw.Reddit(
client_id=<your-client-id>,
client_secret=<your-client-secret>,
user_agent="<your-app-name> by u/<your-username>"
)
From there, requesting submissions (reddit posts) is as easy as:
- Define the subreddit
subreddit = reddit.subreddit("hellofresh") - Make a request type
for post in subreddit.hot(limit=1000): # .new() or .top() etc usage limit 100/min - Parse the returned JSON
posts.append({ "id": post.id, "title": post.title, "score": post.score, "author": str(post.author), "created_utc": post.created_utc, "num_comments": post.num_comments, "selftext": post.selftext, "url": post.url })
For more information you can read through the documentation
Sentiment Analysis NLTK / SIA / VADER
We’re interested on understanding the sentiment of a reddit post. Two sources of information could be used for that purpose: The title, and the post text (called selftext from the api).
VADER (Valence Aware Dictionary for Sentiment Reasoning) was built for social media text sentiment analysis.
The sentiment analysis is scaled from -1.0 to 1.0 where:
- +1 is the most postive sentiment
- 0.0 is neutral
- -1 is the most negative sentiment
So, generally speaking, >0.5 is postive, between -0.5 and +0.5 is neutral, and below -0.5 is negative.
Interaction with these systems is relatively straightforward today:
# Import packages
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
# Setup vader sia
nltk.download('vader_lexicon')
sia = SentimentIntensityAnalyzer()
# Get the sentiment scores from title and selftext
df["title_compound"] = df["title"].fillna('').apply(lambda x: sia.polarity_scores(x)['compound'])
df['selftext_compound'] = df['selftext'].fillna('').apply(lambda x: sia.polarity_scores(x)['compound'])
Data Cleaning
With the sentiment ready let’s take a look at how the title and selftext correlate.
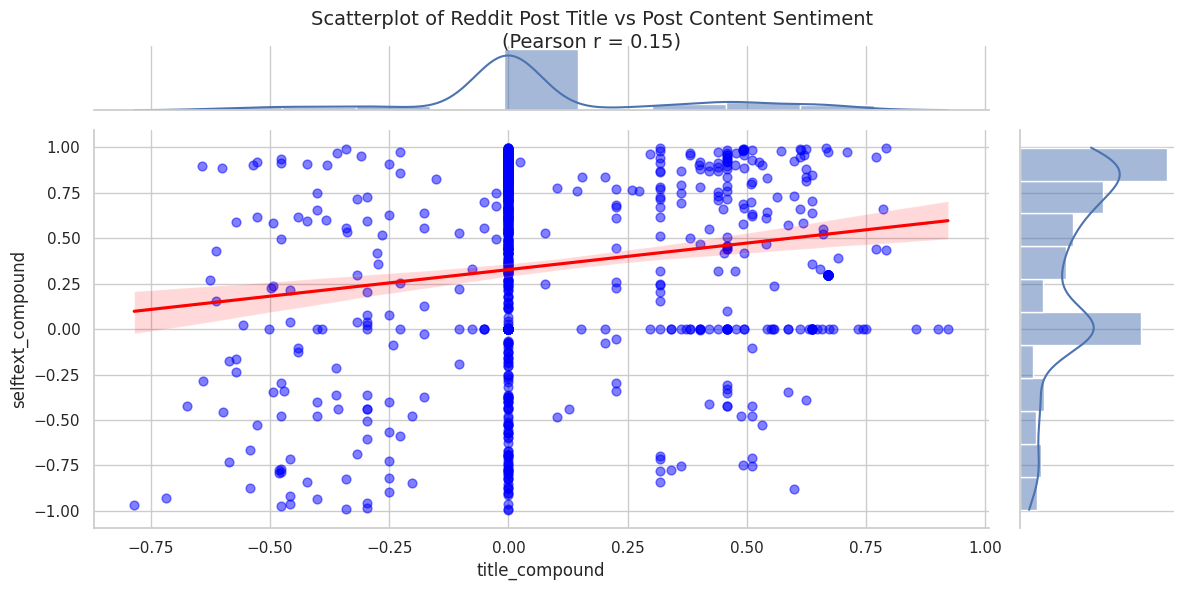
Immediately you can see a value of 0.0 (totally neutral) was extracted very often from the title, and a few times from the self text. The titles are limited in length, so there might not acually be enough information to judge if the post is positve or negative.
Second to the neutral titles issue, there are some negative title sentiments with positive self text (top left) and positive titles with negative self text (bottom right) - the only reason I can think of for the contradiction is sarcasm
Of the options of dealing with this I considered:
- Pick title or self text not both
- Remove any posts with contradictory sentiment
- Weight the selftext more than the title
- Stick with an averaging method for a compound sentiment
These aren’t great options - each adds its own bias, so let’s take a look at what these might look like distribution wise.
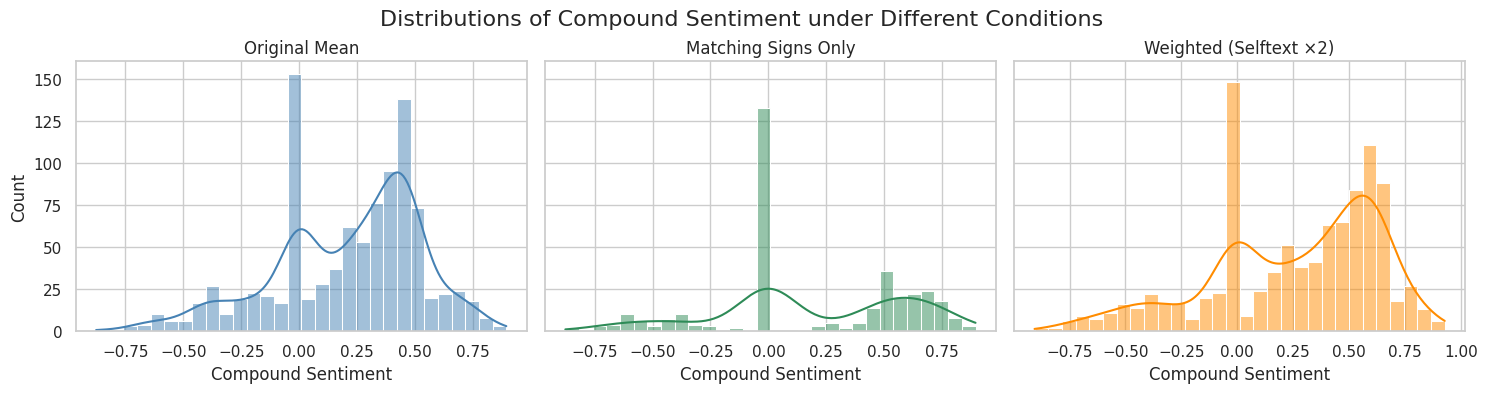
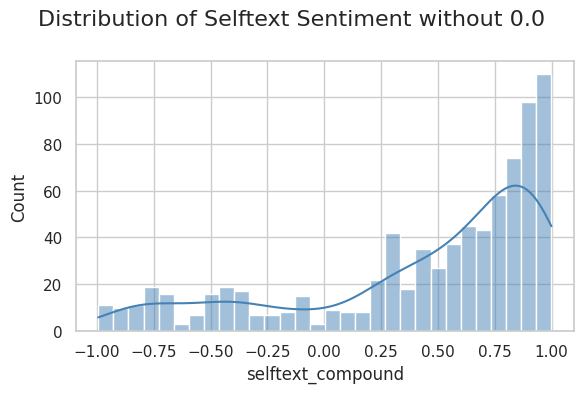
We’re now really seeing the effect of those 0.0 sentiment scores. The distribution behind them is skewed to the left and has zeros pulling the averages down. At this point, because the title doesn’t have a ton of context, and because of the 0 skewing, I decided to drop the 0.0 scores from continued analysis and just stick with the selftext sentiment.
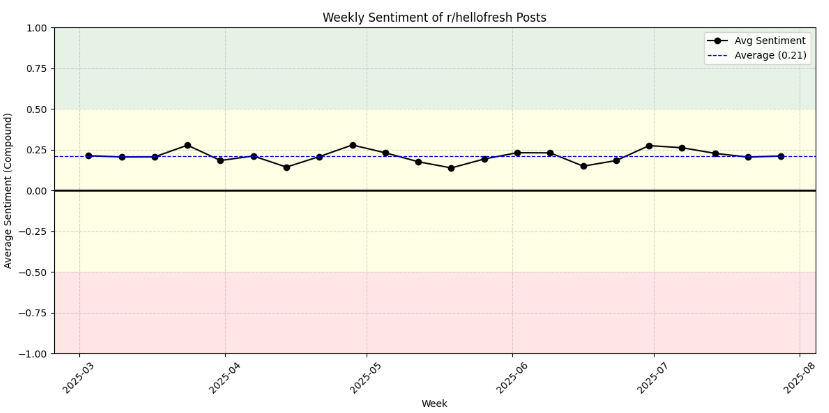
Sentiment aggregation - how is the r/hellofresh sentiment over time?
We have a few options for aggregating a sentiment score over time - just the day it was made, or aggregated by some time bucket - we’ll use weekly.
Then, we could use the mean, the median, a range, or porportions of good vs bad. Let’s take a look at the options.
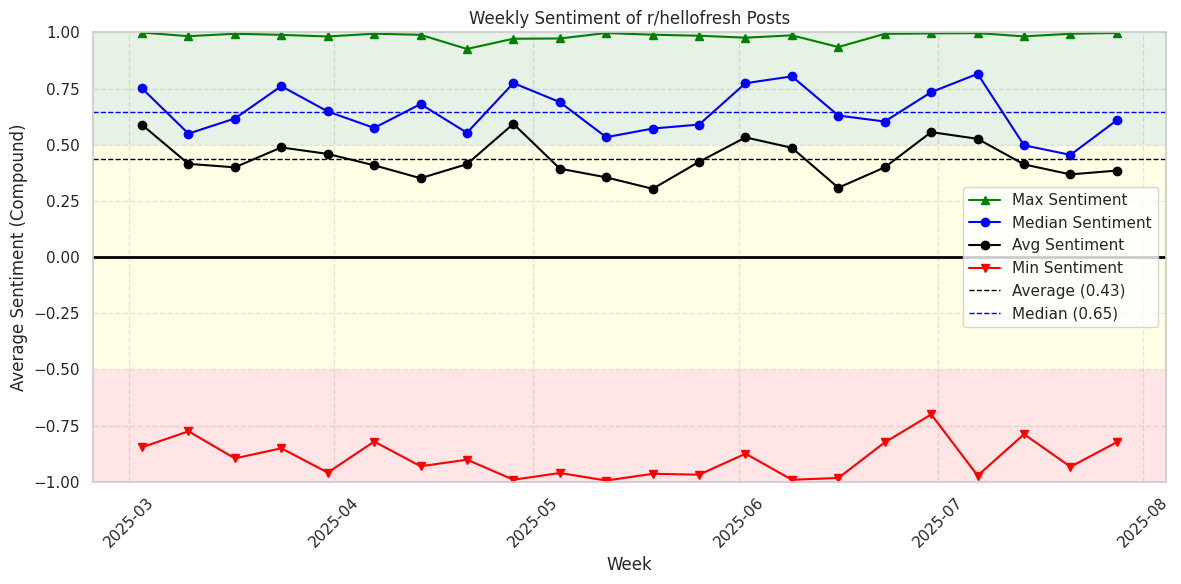
The mean shows neutral to positive over time and the median shows more positive. They both follow the same general trend.
We also do have a very full range of sentiment with the min and max both reaching the outer limits. Let’s see what we can learn about the negative feelings.
BERT Clusters - when negative sentiment, what is going wrong?
Let’s see if there are any similarities between negative comments. BERT (Bidirectional Encoder Representations from Transformers) learns relationships between words. This was trained on a massive amount of text and instead of just sentiment, it weighs the importantce of sentences when processing it.
Setting up for BERT is straightforward as well:
# Import BERT and create a model for processing
from bertopic import BERTopic
topic_model = BERTopic(language='english', verbose=True)
# Take the very negative posts and convert to a list for BERT
neg_df = df[df['selftext_compound'] <= -0.5].copy()
docs = neg_df['selftext'].astype(str).tolist()
# Fit the BERT model to the data
topics, probs = topic_model.fit_transform(docs)
# View topics
topic_model.get_topic_info()

The first run of this gave us some really crappy topic categories. This is because our text still has ‘stop words’ - very generic common words that should just be left out because they don’t add to the topic. We can clean that with a stopword dictionary from nltk with some specific additions in {} :
from nltk.corpus import stopwords
nltk.download('stopwords')
stop_words = set(stopwords.words('english')) | {"im", "ive", "dont", "youre", "also", "get", "got", "just", "really", "like"}
def clean_text(text):
text = text.lower()
text = re.sub(r"[^a-z\s]", "", text) # remove punctuation/numbers
text = " ".join([word for word in text.split() if word not in stop_words])
return text
cleaned_docs = [clean_text(doc) for doc in docs]
By rerunning on the cleaned matrix we get a list of topics that relate to the very lowest scores:

As a third pass, now including any score that’s slightly negative (selftext_compound < 0) we can get a third topic grouping:
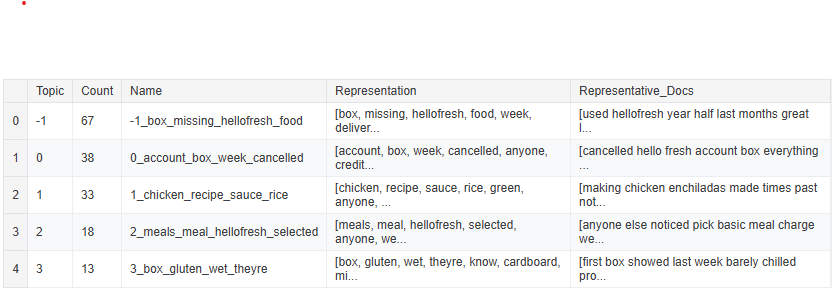
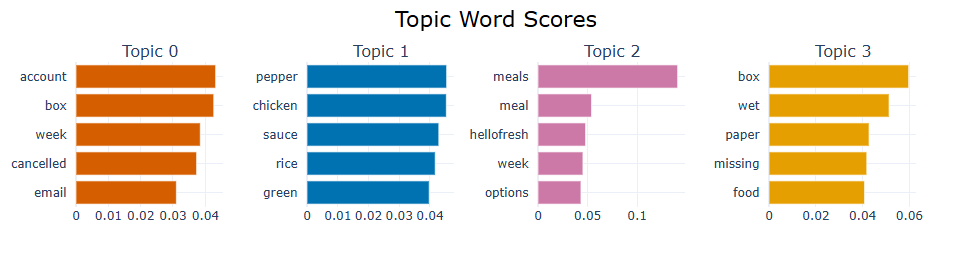
Issues:
- Something about their accounts being canceled or box credits
- Something about a recipe for a spicy chicken with rice dish (enchiladas maybe)
- Something about weekly options and basic meal charges
- Something about wet boxes or temperature issues & gluten free
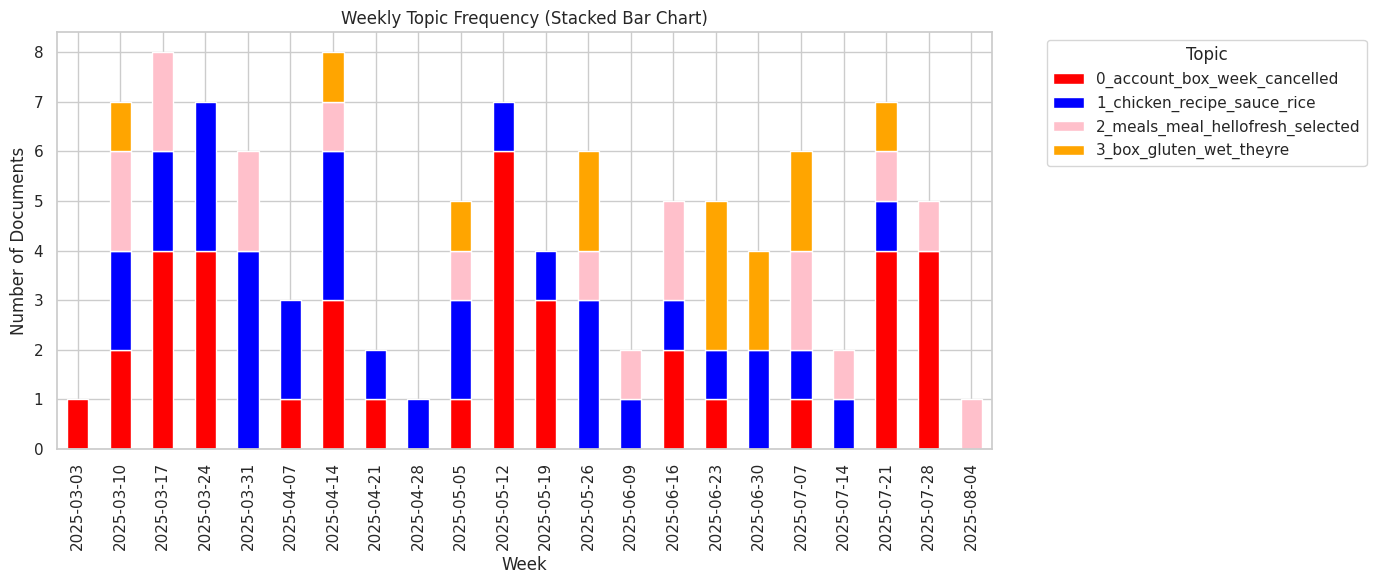
Issues over time
It looks like the cancellation, meal options, and spicy chicken and rice problems happen fairly regularly.
The wet paper missing comments seemed to be infrequent but upticked slightly mid june.
Next Steps
If we wanted to expand on this style of analysis the next place to add data would be the comments. Often people pile on to threads. We’d want to start to deduplicate comments within posts by author though to avoid supersampling really happy or really unhappy redditors. From there we could take the same steps, or even use BERT for the sentiment analysis too.
On all of our minds today, too: What about AI? VADER and BERT are relatively old by comparison - it would be interesting to validate/get a second opinion from an AI model run on the dataset. If the results are interesting, I’ll post them here.
Ultimately though, even with all of this cleaning - the reddit community is just ‘one group’ of consumers, it can add context to the company’s external evaluation, but shouldn’t be used as a sole resource.